
U-Net in U-Net for Infrared Small Object Detection
最近看到一篇文章比较有意思,是对在图像分割领域的”常青树”u-net做的改进,由于自己之前在实验室做过图像分割的项目,曾经也魔改了一版u-net,所以对相关的工作还是比较感兴趣的。这篇论文的题目就很吸引眼球,UIU-Net,在u-net里面套了一个u-net,话不多说,让我们来看看具体是怎么做的。
背景
本文旨在研究红外小目标检测问题,并提出一种基于深度学习的U-net in U-net 方法来提高检测性能,在这一部分,作者首先介绍了红外小目标检测的背景和相关研究。
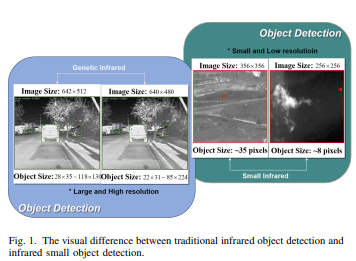
红外小目标检测是一项重要的研究领域,在许多应用中都具有重要的研究价值,如军事侦查、目标跟踪、航空航天和安防等。与可见光相比,红外图像具有更高的对比度和更强的穿透力,可以穿越烟雾、雾霾等环境,且不受光线干扰。因此,红外图像可以更好地获取目标的信息,特别是在夜间和恶劣天气的条件下。
然而,红外小目标检测是一项具有挑战性的任务。由手红外小目标的特征不明显,目标尺寸小、形态不规则,加之背景复杂多变,对检测算法的要求较高。传统的基手特征工程的方法通常需要人工设计特征,此难以达到最佳效果。近年来,深度学习技术的发展为红外小目标检测带来了新的机遇。
目前,已经有很多学者通过深度学习方法对红外小目标检测进行了研究。其中,一些深度学习方法包括基于卷积神经网络(CNN)的方法、基于循环神经网络(RNN)的方法、基于卷积和循环神经网(CNN-RNN) 的方法等。这些方法在一定程度上提高了红外小目标检测的性能,但是仍然存在一些问题,如对小目标的检测灵敏度不高、对背景的适应性不够等。
因此,本文提出了一种新的U-Net in U-Net方法,用手提高红外小目标检测的性能。该方法利用U-Net网络的优势,堆叠两个U-Net网络,提取更好的特征和增强对小目标的检测灵敏度和准确性。同时,引入了多尺度图像金字塔结构和注意力机制,进一步提高了检测性能。该方法具有良好的可扩展性和通用性,可以应用于其他因像分割和目标检测任务。
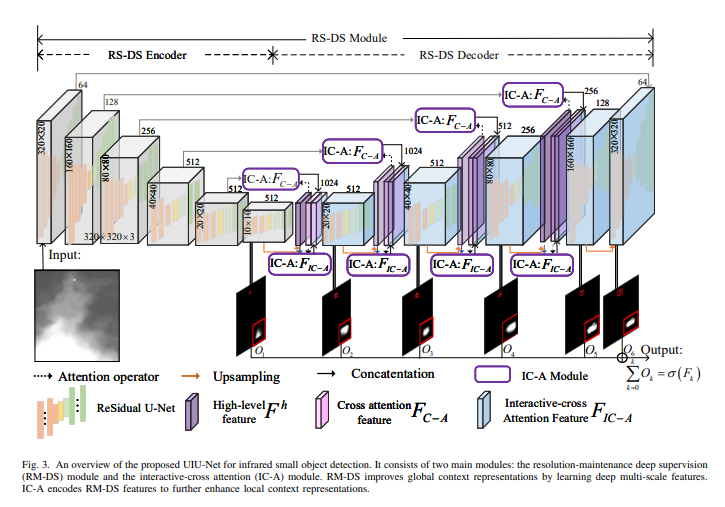
方法
本文提出了一种名为U-Net in U-Net的方法,用于提高红外小目标的性能。该方法将两个U-Net网络嵌套在一起,用于提取更好的特征和增强对
小标的检测灵敏度和准确性。本章节将从以下几个方面详细介绍该方法的具体实现步骤。
多尺度图像金字塔结构
在红外小目标检测中,目标的大小可能会发生变化,因此需要使用不同尺度的图像来进行处理。在U-Net in U-Net方法中,我们采用了一种多尺度图像金宇搭结构,用于提高对不同大小目标的处理能力。该结构包括一组不同尺寸的国像,以便网络可以处理不同大小的目标。
在每个尺寸下,都使用了一个U-Net网络来提取特征,这些特征将被传递到下一尺寸的U-net网络中,以进一步提取和处理特征。通过使用多个不同尺度的图像,U-Net in U-Net方法可以更好地处理不同大小的目标,从而提高检测性能。
注意力机制
在红外小目标检测中,小目标的检测是一个具有挑战性的问题。为了增强对小目标的检测灵敏度,我们采用了一种注意力机制,以过滤掉不相关的特征,同时增强与小目标有关的特征。
该机制引入了一种基于特征的门控机制,以过滤掉不相关的特征,并增强与小日标相关的特征。具体来说,我们通过卷积操作将特征图转换为一组特征向量。
然后,通过使用门控机制来过滤不相关的特征,并增强与小目标相关的特征。最后,我们将过滤后的特征向量重新转换回特征图,以供后续处理使用。
通过过滤不相关的特征,注意力机制可 以使网络更好地关注与小目标相关的特征,从而提高对小目标的检测灵敏度和准确性。
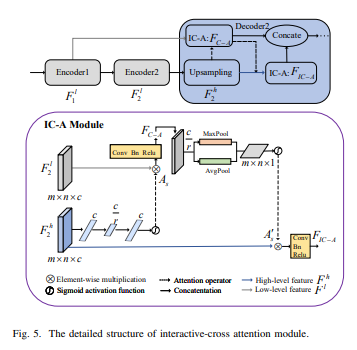
本文提出了一种Interactive-cross Attention (IC-A) Module,如上图所示。
- 首先,将输入图像通过第一个U-net进行特征提取。
- 然后,将特征图像输入到IC-A模块中,该模块包含了一系列迭代的上下文聚合,用于提取不同尺度的特征。
- 在每个迭代中,IC-A模块将上一层的特征图像沿着不同的方向(上、下、左、右)进行卷积操作,并将得到的特征图像与上一层特征图像相加,以产生新的特征图像。这样可以在不同的尺度上捕获更多的上下文信息。
- 通过多次迭代,IC-A模块可以在不同的尺度上聚合上下文信息,从而获得更准确的检测结果。
U-Net in U-Net网络架构
U-Net in U-Net方法堆叠了两个U-net网络,用于提取更好的特征和增强对小目标的检测灵敏厦和准确性。第一个U-Net网络用于提取图像的特征,第二个U-Net网络则用于小目标的检测。这两个网络都使用了 卷积神经网络(CNN) 夹提取特征,并通过跳跃连接进一步提高检测性能。第一个U-Net网络由编码器和解码器部分组成。编码器部分采用卷积和最大池化操作,用于提取特征。解码器部分则采用反卷积和上采样操作,将特征区映射回原始图像大小。这个网络的输出是特征图。第二个U-Net网络也由编码器和解码器两部分组成。编码器部分采用与第一个U-Net网络相同的卷积和最大池化操作。解码器部分也采用反卷积和上采样操作,将特征图映射回原始因像大小。不同的是,第二个U-Net网络的输出是概率图,用于表示每个像素点是否属于小目标。
在训练过程中,我们使用二元交叉熵损失函数来优化模型,计算网络输出概率图与标注图像之问的差异。我们使用Adam优化算法来更新网络参数,训练过程是一个端对端的过程,同时对两个U-Net网络进行优化。
在测试过程中,我们对每个尺度的图像进行检测,在不同尺度的检测结果上应用非极大值抑制 (NMS) 算法,以过滤掉重叠的检测结果。最终,我们将所有尺度的检测结果合并,得到最终的检测结果。
该方法的主要优点在于堆叠了两个U-Net网络,减少了对特征的丢失和信息的混淆。通过跳跃连接,网络可以从不同层级的特征图中获取更准确的信息,从而
提高检测性能。此外,该方法还具有良好的可扩展性和通用性,可以应用于其他图像分割和目标检测任务。
总结
除此之外,本文还介绍了使用的数据增强的方法,主要是对图像进行了随机旋转、缩放等,不过这都是很常见的预处理方法了,总的来说作者的思路比较新颖,对U-net做的改进也比较有意思,但是没有看到对参数量以及推理时间的实验,个人怀疑这种方式的推理耗时可能增加的不少。不过能看到比较有意思的CV工作换换口味还是挺不错的~