
强化学习笔记3————Qlearning和SARSA
前面我们学习了如何使用蒙地卡罗(MC)和时序差分(TD)方法来更新一个节点的V值,注意这里的节点指的是状态节点$S_t$,但是在实际的情况中,我们更希望的是知道在该状态下,进行不同的动作$Q$获得的Q值,这样只要知道某个状态下所有动作值的奖励值,也就是知道了具有最高奖励值的是哪个动作,然后直接采取这个动作就行。
TD之于Q值估算
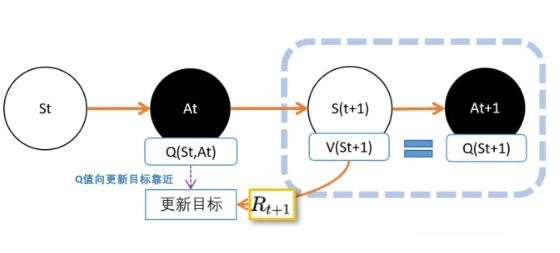
我们现在用上TD的思路。我们在 $St$,智能体根据策略pi,选择动作$A_t$,进入$S{(t+1)}$状态,并获得奖励R。 如果你之前对V和Q的理解足够深,那么不难理解上面这张图。$V(St+1)$的意义是,在 $S_{(t+1)}$ 到最终状态获得的奖励期望值。 $Q(S_t,A_t)$ 的意义是,在$Q(S_t,A_t)$到最终状态获得的奖励期望值。 所以我们可以把$V(S_t+1)$看成是下山途中的一个路牌,这个路牌告诉我们下山到底还有多远,然后加上R这一段路,就知道 $Q(S_t,A_t)$ 离山脚有多长的路。
但在实际操作的时候,会有一个问题。 在这里我们要估算两个东西,一个是V值,一个是Q值。
人们想出的办法就是,用下一个动作的Q值,代替V值。因为从状态$S{(t+1)}$到动作$A{t+1}$之间没有奖励反馈,所以我们直接用 $A{t+1}$ 的Q价值,代替$S{(t+1)}$价值。 这样不就是可以了吗?
还有一个问题:在$S{t+1}$下,可能有很多动作$A{t+1}$。不同动作的Q值自然是不同的。 所以$Q(S{t+1},A{t+1})$并不能等价于$V(S_{t+1})$。
虽然不相等,但不代表不能用其中一个来代表$V(S{t+1})$。人们认为有个可能的动作产生的Q值能够一定程度代表$V(S{t+1})$。
- 在相同策略下产生的动作$A_{t+1}$。这就是SARSA。
- 选择能够产生最大Q值的动作$A_{t+1}$。这就是Qlearning。
SARSA
为什么SARSA用相同策略下产生的动作At+1是合理的。答案很简单,它管用。 其实在强化学习,虽然涉及很多数学,但它并不是严谨科学,它更像是工业,只要实际操作管用就行。
现在我们回到SARSA:
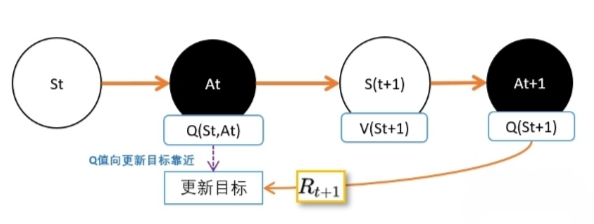
其实SARSA和我们上一篇说的TD估算V值几乎一模一样,只不过我们挪了一下,从V改成Q了。
注意,这里的$A{t+1}$是在同一策略产生的。也就是说,$S_t$选$A_t$的策略和$S{t+1}$选$A_{t+1}$是同一个策略。这也是SARSA和Qlearning的唯一区别
Qlearning
Qlearning能够产生最大Q值的动作$A{t+1}$的Q值作为$V(S{t+1})$的替代。
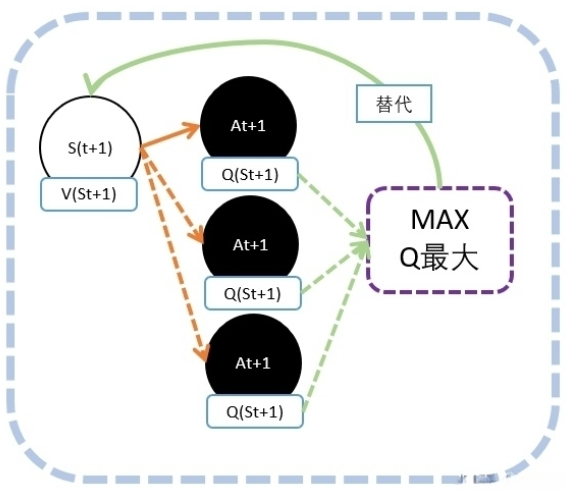
道理其实也很简单:因为我们需要寻着的是能获得最多奖励的动作,Q值就代表我们能够获得今后奖励的期望值。所以我们只会选择Q值最大的,也只有最大Q值能够代表V值。
Qlearning算法流程
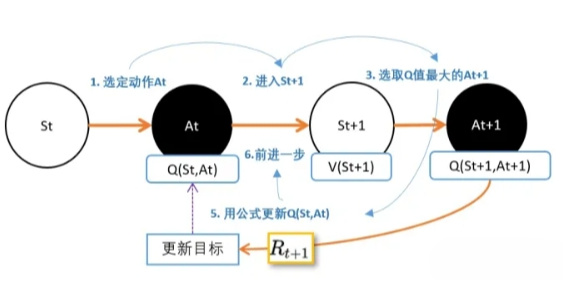
我们现在重新整理下,Qleanring的更新流程。 我们将会在任意的state出发
- 我们将会用noisy-greedy的策略选定动作A
- 在完成动作后,我们将会进入新状态St+1;
- 检查St+1中所有动作,看看哪个动作的Q值最大;
- 用以下的公式更新当前动作A的Q值;
- 继续从s’出发,进行下一步更新 1-6步我们作为一个EP,进行N个EP的迭代。
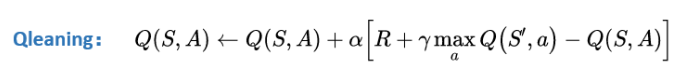
在具体实现的时候,有两个方式需要注意:
Q-table
Q-table(Q表格) Qlearning算法非常适合用表格的方式进行存储和更新。所以一般我们会在开始时候,先创建一个Q-tabel,也就是Q值表。这个表纵坐标是状态,横坐标是在这个状态下的动作。
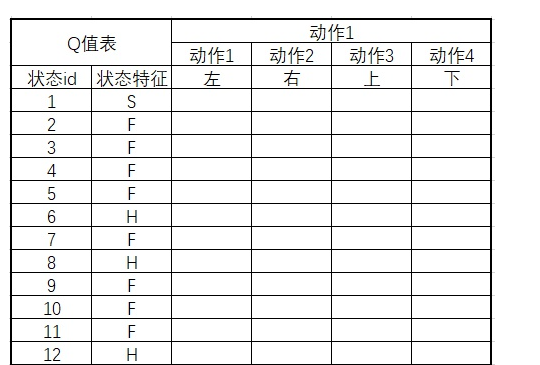
我们会初始化这个表的值为0。我们的任务就是,通过算法更新,把各个状态下的动作的Q值,填到上面去。
noisy-greedy
之前说过,在选择动作的时候,理论上每次都会使用当前状态下,Q值最大的动作。这样的选择方式,我们称为“贪婪”(greedy)。
因为我们只选择Q值最大的动作,所以有一些动作没被更新过没有被选择的过的动作,将更新不到。Q值也永远为0。
举个例子:
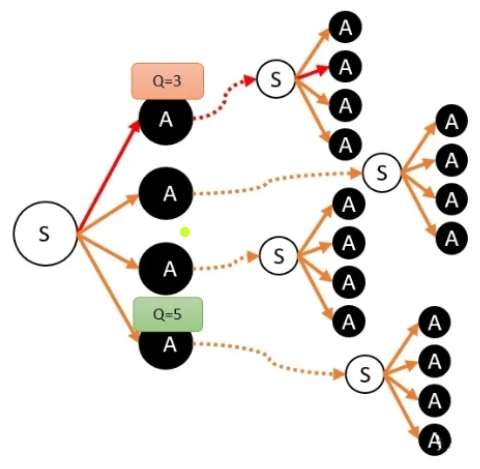
假设某次智能体经过路径(途中的红色线路),根据Qlearning算法更新公式,我们计算得到某动作Q值为3。
由于其他动作还没执行过,因此他们保持初始值(一般为0)。按照贪婪算法,下一次智能体来到S的时候,会选择Q值最大的动作,也就是Q=3。于是红色路径再次被执行,Q值被更新。然后再一次,智能体仍然只会选红色线路。
但事实上,Q值最大的可能是其他的动作,但其他动作没有Q值,只是因为没有被“探索”出来。事实上我们会希望智能体在开始的时候更多随机行走去探索,而后面更多按照Q值去走动。在每次选择动作的时候,就给我们要选择的动作叠加一个噪音。所谓噪音,就是在原来的值上增加一个随机值。注意!这些噪音只是在选择的时候,临时加上,每次都随机的。只干扰了当前选择,并不会影响真正的Q值。当我们认为智能体对环境的了解已经足够充分,我们就可以慢慢减少噪音的大小。在实做中,我们只需要在我们每次游戏后,将会减少产生噪音的方差,这样对干扰仍然有干扰,但这种干扰将会逐渐减少。直到相对于真正的Q值没有影响的程度。最终,agent将会按照自己的策略选择动作。
训练过程
那我们如何使用noisy-greedy策略来更新Q值呢,这里我们看看代码:
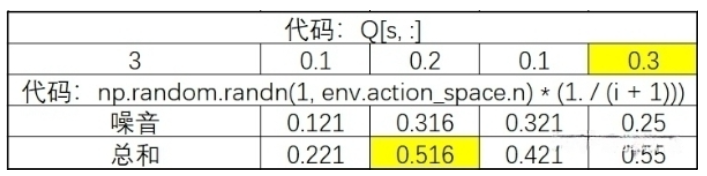
1 | a = np.argmax(Q[s, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1))) |
这一行代码我们可以切开几个步骤来看一下:
- 首先,Q[s, :] 我们看一下table表的s行,就是我们当前的状态对应各个动作的Q值。
- 其次,np.random.randn(1, env.action_space.n) 就是我们制造出来的噪音,我们希望噪音随着迭代的进行,将会越来越小。 因此我们乘以 (1. / (i + 1))。当i越来越大的时候,噪音就越来越小了。
- 最后,我们通过np.argmax()获得最大Q值对应的列号,也就是对应的动作。这里要注意,argmax找出最大值后,并不是返回最大值,而是返回最大值的列号,也就是动作。同学在这里要注意理解,我们需要的是动作A,而不是Q值。
1 | s1, r, d, _ = env.step(a) |
env.step() 我们把动作传入到环境中,环境会给我们返回4个返回值。
- new_state: 示例代码用s1表示。这个表示我们执行动作后,新的状态。
- reward: 示例代码中用r表示,执行动作a后,获得的收获
- done:一个标志位,表示这个是否最终状态。
- _ : 其实是info,但我们一般用不到这个值;因此我们把它先忽略。
1 | Q[s, a] = Q[s, a] + lr (r + lambd np.max(Q[s1, :]) - Q[s, a]) |
我们用newstate的Q值,更新我们现在状态的Q值。我们对应更新公式,就很容易理解了。 注意比较:这里np.max和之前np.argmax函数的区别在于,np.max是返回最大值。而np.argmax返回时最大的行数或者列数。
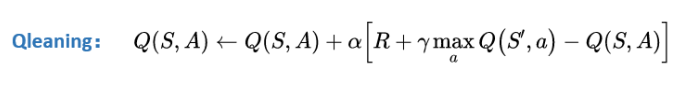
最后,我们更新Q值的任务已经完成,把游戏进行下去。把下一个状态s1赋值给s,重新开始新一步,和新一步的更新。
但在开始之前,我们检查一下,下一个状态是否就是终止状态了,如果是,这一次游戏就算是完成,开始一次迭代。
总结
Qlearning和SARSA是多么鼎鼎大名,但直觉上理解还是很简单的。
现在我们来总结一下整个思路: 1. Qlearning和SARSA都是基于TD(0)的。不过在之前的介绍中,我们用TD(0)估算状态的V值。而Qlearning和SARSA估算的是动作的Q值。 2. Qlearning和SARSA的核心原理,是用下一个状态St+1的V值,估算Q值。 3. 既要估算Q值,又要估算V值会显得比较麻烦。所以我们用下一状态下的某一个动作的Q值,来代表St+1的V值。 4. Qlearning和SARSA唯一的不同,就是用什么动作的Q值替代St+1的V值。 - SARSA 选择的是在St同一个策略产生的动作。 - Qlearning 选择的是能够产生最大的Q值的动作。