
When Search Meets Recommendation
现代在线服务提供商(如在线购物平台)通常提供搜索和推荐(S&R)服务,以满足不同的用户需求。很少有有效的方法可以有效的利用S&R服务中的用户行为数据。大多数现有方法要么只是单独处理S&R行为,要么通过聚合来自两种服务的数据来联合优化它们,忽略了S&R中用户意图是有着明显的不同这个前提条件。在这篇论文中,我们提出了一种Search-Enhanced的架构,将用户的搜索意图用于序列推荐。具体来说,SESRec利用用户的搜索query以及item的交互来计算其embedding的相似度,这里使用了两个独立的transformer编码器去学习上下文的表达。然后设计了一个对比学习任务作为学习到的相似和不相似的表达的监督。最后,我们通过三个角度(即上下文表示、包含相似和不相似兴趣点的两个分离行为)使用注意力机制提取用户兴趣。
Learning Disentangled Search Representation for Recommendation
背景
目前,随着互联网数据的大量增加,仅使用推荐系统或搜索引擎不能满足用户的信息需求。因此,许多社交媒体平台(如YouTube和TikTok)为用户提供搜索和推荐服务,以获取信息。由于用户在两种情境下表达了各自的兴趣,因此通过联合建模两者的行为来增强推荐系统是可行的,而核心挑战在于如何有效地利用用户的搜索兴趣来捕捉准确的推荐兴趣。
大多数先前的工作忽略了用户在搜索和推荐行为中的兴趣差异,在建模时不考虑它们之间的相关性。然而,在现实世界的应用中,搜索行为可能会加强或补充推荐行为中所揭示的兴趣。例如,图1(a)展示了短视频场景下用户部分行为历史记录。当用户浏览推荐系统建议的视频/商品时,他们可能会自发地开始搜索,这些搜索通常与推荐流中的视频内容不同。我们将这种情况称为自发搜索。相反,用户也可以通过点击与当前正在播放的项目/视频相关的建议查询来开始搜索,我们将其称为被动搜索。为了验证这种现象的普遍性,我们从快手应用程序收集的真实数据进行了数据分析,如图1(b)所示。数据分析基于数百万用户的行为。对于每个搜索行为,如果项目的类别存在于用户在过去七天内与之交互的项目的类别集中,则该搜索行为类似于最近的推荐行为,否则不相似。类似的搜索行为反映了用户在推荐行为中重叠的强烈兴趣,并应加强。不相似的行为可能是未被发现的兴趣,这些兴趣可能是新兴的,并且在推荐流中没有得到满足。因此,分离S&R行为之间的相似和不相似表示至关重要。

为了解决这个问题,我们设计了一个名为SESRec的搜索增强框架,在推荐时同时学习解耦后的搜索表达。具体而言,为了解耦两个行为之间的相似和不相似兴趣,我们提出将每个历史序列分解为两个子序列,分别表示相似和不相似的兴趣,以便我们可以从多个方面提取用户兴趣。为了学习两个行为之间的相似性,我们首先基于用户的query-item交互,使用InfoNCE损失来学习query-item的embeddings。然后,我们使用两个单独的编码器来建模S&R行为并生成它们的上下文表示。由于缺乏label来表示所获得的上下文表示之间的兴趣相似性,我们提出利用自监督来指导学习相似和不相似的兴趣。具体而言,我们利用co-attention机制来学习S&R上下文表示之间的相关性。基于co-attention分数,对于两个上下文表示,我们不仅将它们聚合起来生成被认为维护S&R共享兴趣的锚点,还将它们分成两个子序列,分别被认为表示S&R之间的相似和不相似行为(分别称为正例和负例)。然后,我们按照对比学习原则设计了一种新的相似性损失函数,以鼓励嵌入空间中的正样本比负样本更接近。通过联合优化InfoNCE损失和相似性损失,我们可以学习到推荐模型的解耦搜索表示。最后,我们使用注意力机制从三个方面提取用户兴趣,即S&R的上下文表示、正例和负例。通过这种方式,S&R行为的解耦兴趣增强了对下一次交互的预测。
方法
problem setting
定义用户、商品、query的集合分别为$\mathcal{U},\mathcal{I},\mathcal{Q}$,对于用于$u \in \mathcal{U}$,定义$Si^u=[i_1,i_2…i{Tr}]$为按照时间顺序的交互商品列表,$S_q^u=[q_1,q_2…q{Ts}]$为用户的搜索历史query,同时,在用户进行搜索时,对每一个query,都可能会有一些交互过的商品,$S_c^u = [i{q1}^{(1)},i{q1}^{(2)},i{q2}^{(1)},i{q2}^{(2)},…i{q{T_s}}^{(1)},i{q{T_s}}^{(2)},i{q{T_s}}^{(3)}]$其中$i{q_{k}}^{(j)}$代表用户在搜索$q_k$时,点击的第$j$个商品。
基于以上定义,我们定义使用搜索数据的序列推荐任务为,给定$Si^u,S_q^u,S_c^u$,去预测用户最有可能点击的下一个item:$P(i{t+1}|Si^u,S_q^u,S_c^u)$,而传统的序列推荐任务可以表示为$P(i{t+1})|S_i^u$
method
SESRec的整体结构如图2所示。首先经过embedding层将稀疏数据稠密化。然后,我们利用transformer层来学习历史行为的上下文表示。为了分离兴趣,我们将两个行为序列分成表示相似和不相似兴趣的子序列。我们将行为序列聚合成向量,以表示用户对候选项的兴趣。最后,我们将所有向量连接在一起,得到整体表示向量,然后使用多层感知机(MLP)生成最终预测。
具体来说,我们设计了几个组件来通过自监督来分离用户兴趣并从各个方面聚合用户兴趣。这些设计的组件在图2中用彩色框表示。我们使用InfoNCE损失将查询和项表示对齐到相同的语义空间中。然后我们分别将S&R行为序列分成子序列。我们利用三元组损失来指导分离的自监督信号。最后,我们引入一个兴趣提取模块,将原始序列和构建的子序列聚合起来,形成行为的聚合、相似和不相似兴趣表示。
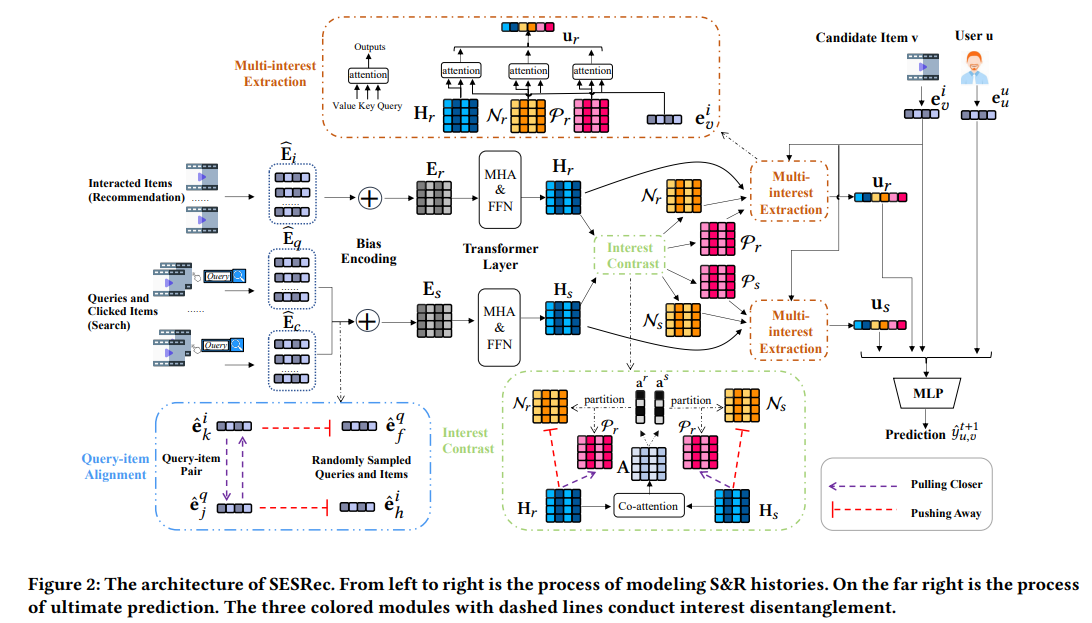
Encoding Sequential Behaviors
Embedding Layer
我们将用户(商品)的表达定义为$e^u = e^{IDu}||e^{a_1}||…||e^{a_n} (e^i=e^{ID_i}||e^{b_1}||…||e^{b_n})$其中$||$表示concat操作,$a,b$分别代表用户、商品的各种属性。特别的对于query,每一个query包含了一些交互items$(w_1,w_2…w{|q|})$,我们将query的embedding定义为query id的embedding与所有相关items的mean poooling之后进行concat。$e^q = e^{IDq}||\text{MEAN}(e^{w_1},…e^{w{|q|}})$ (这个操作其实增加了query的丰富性,因为搜索中有大量的重复query,单纯用id embedding 很难区分)
这时我们就可以将用户的item序列、query系列、以及query交互序列的embedding表示出来$\text{E}_i \in \mathbb{R}^{T_r \times d_i},\text{E}_q \in \mathbb{R}^{T_s \times d_q},\text{E}_c \in \mathbb{R}^{T_r \times d}$,特别的,对于搜索来说,用户可能从不同的source进行搜索,比如用户输入的、历史搜索的、还有当前item相关的搜索等,这些组成了搜索域的embedding矩阵$\text{M}_s \in \mathbb{R}^{k \times d}$,其中$k$代表所有的搜索域数量。
由于在不对齐的向量空间中使用查询和物品表示来建模用户兴趣非常具有挑战性,因此我们将item和query的embedding转换为具有相同的维度。计算方式为:
其中$\text{W}_i \in \mathbb{R}^{d_i \times d},\ \text{W}_q \in \mathbb{R}^{d_q \times d}$,这样处理后,item序列、query系列、以及query交互序列都会变成$d$维。
Bias Embedding
为了建模用户序列的顺序,我们设计了可学习的position embedding分别用于item序列以及query序列,$\text{P}_r \in \mathbb{R}^{T_r \times d},\ \text{P}_s \in \mathbb{R}^{T_s \times d}$,最终得到的item序列Embedding为:
对于query序列来说要复杂一点,除了position embedding外,我们还设计了type embedding,$\hat{\text{M}_s}$。
其中,$\tilde{\text{E}_c} \in \mathbb{R}^{T_s \times d }$为在当前query下,所有交互过的item的embedding的mean pooling。type embedding$\hat{\text{M}_s} \in \mathbb{R}^{T_s \times d }$定义为搜索历史中每个query的类型嵌入序列, 其中,$\hat{M_s}$中的每个元素是从查找表 $M_s$ 中获得的。以模拟搜索行为和搜索来源之间的相关性。
Transformer Layer
为了学习给定序列中每个元素的增强上下文表示,我们使用Transformer层来捕捉S&R序列中每个元素与其他元素之间的关系。Transformer层通常由两个子层组成,即多头自注意力层和点式前馈网络。我们分别将Transformer层应用于S&R序列:
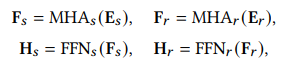
Self-supervised Interest Disentanglement
正如之前提到的,搜索和推荐行为之间的用户兴趣存在重叠和差异。由于不存在任何用户兴趣的注释标签,我们利用对比学习技术来通过自我监督解开搜索和推荐行为,并从三个方面提取用户兴趣,即聚合行为、包含相似和不相似兴趣的两个分离行为。
Query-item Alignment
行为编码器面临的挑战是共同学习具有不对齐embeddings的S&R行为中的用户兴趣。此外,如果不知道query-item之间的语义相似性,则无法将用户兴趣与S&R行为分离开来。因此,在进一步从中提取用户兴趣之前,我们如下对query-item的嵌入进行对齐。由于项目和查询具有不同形式的特征,它们原始的嵌入在不同的向量空间中不对齐。如方程(1)所示,我们首先将query-item的embeddings转换为相同的维度。然后,受到多模型学习工作的启发,我们利用对比学习损失来教导模型哪些query-item是相似或不同的。我们之前得到的query系列、以及query交互序列为:$\hat{\text{E}q}=[\hat{e_1^q},\hat{e_2^q},…\hat{e{Ts}^q}] \in \mathbb{R}^{T_s \times d}$,$\hat{\text{E}_c}=[\hat{e_1^i},\hat{e_2^i},…\hat{e{S_c^u}^i}] \in \mathbb{R}^{|S_c^u| \times d}$
我们最小化如下两个InfoNCE损失的和,一个是query-to-item,另一个是 item-to-query。
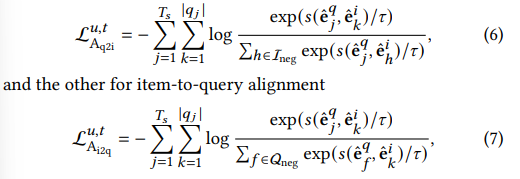
其中,$\tau$是可学习的温度系数,$|qj|$表示在某个query下,用户点击商品的数量,满足$\sum{j=1}^{Ts} |q_j| = |S_c^u|$,$\mathcal{I}{neg},\mathcal{Q}_{neg}$分别是随机采样的items和querys,$s$为相关性函数,$s(p,q) = \tanh(p^TW_Aq),W_A \in \mathbb{R}^d \times d$,(这里的w参数矩阵可以使得在计算q-i的相关性时,与在线推理时可以不同)最终的Query-item Alignment 损失函数如下:
Interest Contrast
为了将相似和不相似的兴趣解耦,我们采用对比学习机制来区分$H_s$和$H_r$的上下文表示中相似和不相似的兴趣。在transformer层之后,给定矩阵$H_s$和$H_r$,我们构建了两个行为的共同依赖表示矩阵,生成了两个序列的相似度分数。我们利用了co-attention技术。我们首先计算一个亲和矩阵$\text{A} \in \mathbb{R}^{T_s \times T_r}$,计算方式如下:
其中,$\text{W}_l \in \mathbb{R}^{d \times d}$是一个可学习的参数矩阵,亲和矩阵$\text{A}$包含与所有推荐行为和搜索行为对应的亲和度分数。我们将亲和矩阵A和搜索矩阵$H_s$(或推荐矩阵$H_r$)相乘,然后对乘积结果进行归一化,以获得一个序列中每个元素在另一个序列中所有元素上的相似度分数:
接下来,我们利用三元组损失来自监督地分离两个行为之间相似和不相似的兴趣。给定相似度分数$\text{a}^s$和$\text{a}^r$,在我们得到的推荐行为序列以及搜索行为序列$H_s$和$H_r$中,分数较高的可以作为兴趣的代表,这里我们使用阈值截断的方式将所有行为分成两个子序列。如下所示:
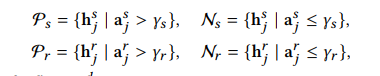
这里由于相似度分数$\text{a}^s$和$\text{a}^r$经过了softmax归一化,阈值设定为$\frac{1}{Ts}$和$\frac{1}{T{r}}$,这样,相似的行为是那些得到大于平均分的,不相似的行为则是得分小于平均分的。
最后,为了使用三元组损失,我们要先定义要锚点、正样本和负样本,
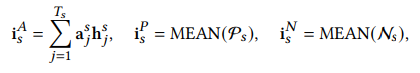
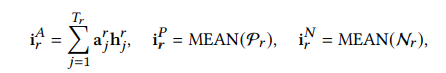
其中,$\text{h}_j^s,\text{h}_j^r$分别为行为序列矩阵$H_s$和$H_r$中第$j$个向量,在对比学习中,我们希望将锚点与正样本的距离拉近,与负样本的距离拉远,那么损失函数可以写成:
$d$时距离度量函数,这里使用了euclidean distance(欧式距离),$m$为控制边界的超参数,$a,p,n$分别表示锚点、正样本与负样本。最后,Interest Contrast 的总loss可以看成是推荐序列的损失和搜索序列的损失的和:
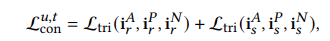
备注。在大多数情况下,用户使用S&R服务的频率不同。由于推荐和搜索的行为序列是从不同的服务中收集的,所以两种行为的长度和更新频率也不同。这就是为什么文章分别对这两种行为采用三元组损失。使用各自构建的兴趣表示来更新每种行为的模型参数,这可以确保模型训练的一致性。此外,考虑到相似和不相似的兴趣通常在一定程度上重叠,它们之间没有明确的区别。三元组损失执行成对比较,减少了相似事物之间的差异,增加了不同事物之间的差异。这就是为什么本文使用三元组损失而不是其他对比损失函数(例如InfoNCE ),后者对正样本和负样本之间的相似性施加了过于强烈的惩罚。
Multi-interest Extraction
基于原始行为和包含相似和不相似兴趣的分离行为,我们从三个方面提取用户兴趣,即聚合兴趣、相似兴趣和不相似兴趣。给定一个候选商品$v$,我们利用注意力机制重新分配用户兴趣,以候选项为中心。对于推荐行为,可以从以下三个方面提取兴趣:
- 聚合兴趣:将用户历史行为中所有与候选项相关的兴趣进行聚合,形成一个全局的兴趣表示。
- 相似兴趣:从用户历史行为中提取与候选项相似的兴趣,例如相同的类别、标签等。
- 不相似兴趣:从用户历史行为中提取与候选项不相似的兴趣,例如与候选项相关的但不同类别、不同标签等。
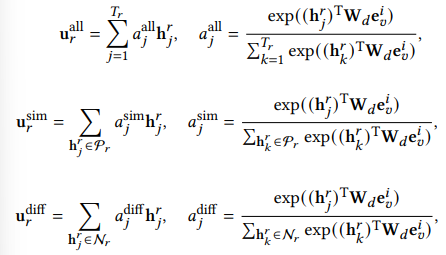
最终将这三个兴趣项拼接起来,就得到了最终的兴趣表征$u_r=u_r^{all}||u_r^{sim}||u_r^{diff}$, 同样的方法可以得到搜索的兴趣表征。
Prediction and Model Training
Prediction
预测的过程相对简单,首先通过上文的模型得到用户的兴趣表征,最后的打分为:
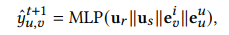
就是将两个兴趣表征(推荐&搜索)加上用户和item的Embedding拼接到一起,过两层MLP算出打分。
Model Training
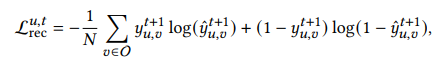
训练时的损失函数如上,其中$\mathcal{O}$是一个batch的训练数据,有一个正样本,N-1个负样本,为了增加额外的query-item的语义相似性和兴趣区分信息,我们用multi-task的方式设计了端到端的模型,总的损失函数如下:
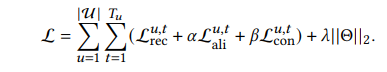
其中,$\mathcal{U}$为user的集合,$T_u$是用户最近的交互行为。$\alpha,\beta$为超参数,后面还增加了L2正则项防止过拟合。
结论
这篇文章的模型虽然不复杂,但是从理论到算法实现都很流畅,从用户的搜索方法以及情景不同,反应到用户的兴趣不同,再到进行推荐时需要考虑到用户的搜索行为以及交互行为,同时使用对比学习的方式将不同行为序列进行提纯,对不同兴趣的划分看起来比较符合实际情况,给出的解法也简单可行。