
MetaSplit Meta-Split Network for Limited-Stock Product Recommendation
从腾讯的PLE之后,很少看到有亮眼的在模型结构上做创新的推荐算法了,大多数的paper还是聚焦于某个独特的业务场景。不过这也合理,推荐算法不像CV,和业务的强绑定导致在业界很难做出本质上的创新。最近看到的一篇闲鱼出品的孤品建模就是一种强业务属性的paper。
首先定义一下孤品和新品的区别,孤品和新品都属于长尾商品,但有几点不同:
- 新品会随着时间而活动足量曝光和交互,孤品由于库存少,质量越好卖得越快下架也越快,导致积累不了太多的用户交互数据
- 占比,在闲鱼app上,新品较少,孤品占比一半多。
难点
收敛性:浅库存商品的存在使得物品和消费者之间的互动变得更加稀疏,导致其Embedding在模型训练过程中收敛速度较慢甚至无法收敛。然而对于ID-based的推荐模型而言,一张训练良好的ID Embedding表可以大大提高模型的推荐能力。因此,浅库存商品的存在对推荐系统中排序模型的训练带来了巨大挑战。
公平性:浅库存、深库存商品在用户历史行为序列中的共存使得用户兴趣建模过程变得复杂,尤其是在序列建模常用的注意力机制过程当中。如表1所示,浅库存的稀疏交互特点,往往会导致其在计算注意力权重的时候被低估;而对于深库存商品往往积累更多用户的交互行为,导致用户序列建模的时候更偏向于深库存商品,从而大大影响整体建模的准确性。
业界方案
- 元学习。通过设计特殊的策略或者网络生成新的商品emb并用来作商品推荐。
- 消偏网络。针对长尾商品的低估问题,该类方法通过设计消偏函数或者采样函数,直接对低估商品的Logit、Loss或者样本进行加权
- 增强个性化。该类方法通过设计专门的门控机制对模型表征进行强化以缓解训练不充分的问题
尝试过的方案
- 为孤品引入泛化特征,采用类似GateNet或FiBiNet的方案给孤品表征加权,对孤品样本采样或Loss加权,使用非孤品模型蒸馏孤品模型
- 构造Mask网络用非长尾商品来fake长尾商品
- 构造Meta网络用来为长尾商品生成缺失的特征值
- 通过孤品优势特征输入Gate网络给孤品加权
MSNet:序列建模的孤品方案
1 通过BC行为序列拆分,避免C品和B品直接竞争而导致C品信息低估;
2 通过元学习网络,让用户序列中C品的商品ID信息和SideInfo信息(如类目、品牌等)互相增强,缓解C品的itemId Embedding学习不充分、难收敛的问题;
3 通过设计辅助Loss,使得C品即使在售出下架之后,对应的Embedding也能够持续保持更新
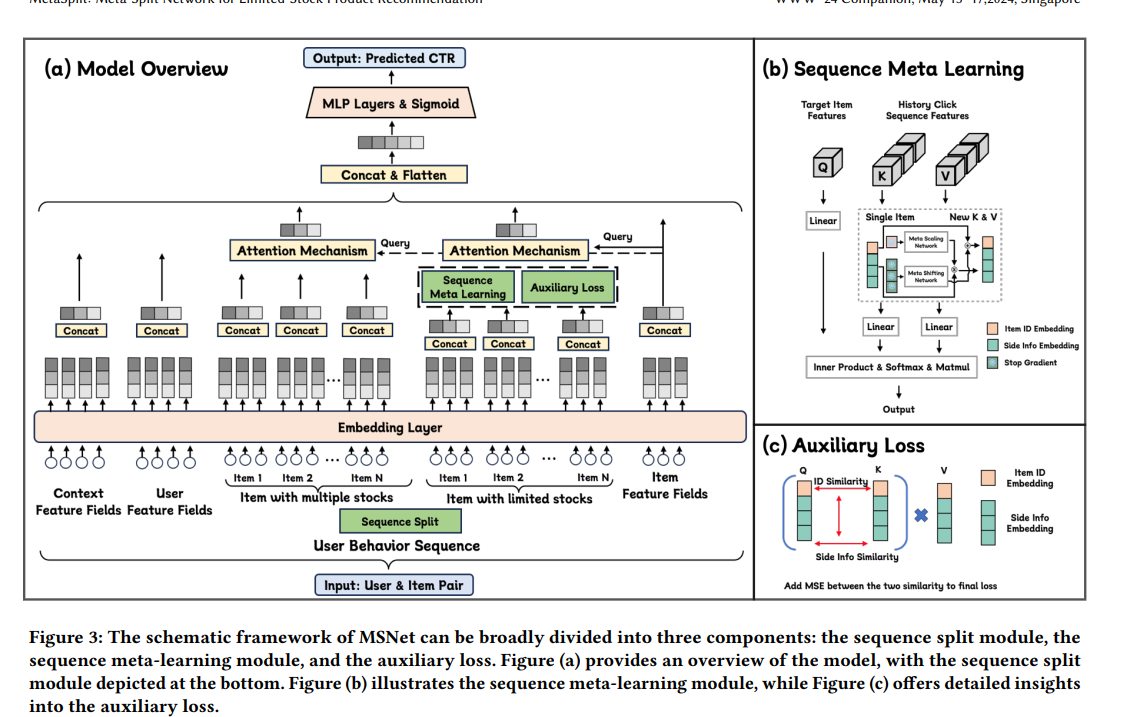
元学习网络
一般来说,具有相似类目、标签、品牌的商品之间也更加相似。因此我们设计了一种元学习模块,希望把这种先验信息利用起来,具体来说,我们设计了一种Scaling&Shifting结构,让序列中C品的ID特征(ItemId)和SideInfo泛化特征(类目、品牌等)之间有选择地互相增强,生成新的商品ID和Sideinfo表征,进而缓解C品Embedding学习不充分的问题,公式如下,其中式(1)用Sideinfo信息增强ID信息,式(2)则用ID信息增强Sideinfo信息:
其中,$\oslash$代表停止梯度回传,$MetaDnn_1$和$MetaDNN_2$是两个元学习网络,分别对商品的原始sideinfo和原始ID做变化,并对输出的向量分别以矩阵加和元素乘的方式融合进入原始信息,生成新的ID和新的sideinfo,在进行后续的用户序列建模。这种方式的有效性在于:
- 针对未训练充分的ID特征,引入学习更加充分的sideinfo信息,弥补ID特征训练不足的问题。
- 如果某个商品的ID特征没有训练充分,模型可以感知到,并主动增强对应的泛化特征的重要性。
辅助Loss模块
上一节解决了C类商品ID的收敛性问题,本节主要解决优质C品的售出即下架的问题。在常规的用户序列建模过程中,当一个商品下架后,它再也无法作为Target商品Q出现,而只能出现在用户序列的K和V中;而由于这些商品本身的Embedding表征并未学习充分,在Q*K相似度计算阶段得到的权重都很小,根据链式求导法则可知其Embedding更新会非常缓慢甚至停止更新。
通过设计辅助Loss模块,让具有相似SideInfo的商品之间的ID特征Embedding也相似,对这些C品的ID特征Embeding进行更新。该方法让QKV中的C品表征均能够得到更新,且更新梯度仅依赖于商品之间的SideInfo是否相似,具体公式如下:
其中式(3)、式(4)分别计算了C品之间的itemId、SideInfo表征的两两相似度,式(5)的辅助Loss用于拉近SideInfo相似的商品之间的itemId表征的距离。这种参数更新模式不依赖商品是否下架,只要这些商品一直存在用户的历史行为序列当中,就能够持续保持更新,如图c所示。
(扩展)近邻扩展:孤品的进一步探索
上一节从用户序列建模的角度审视推荐系统的孤品问题,提出了一种系统的解决方案即MSNet网络,设计并采用「序列拆分」、「元学习网络」以及「辅助Loss」等模块让C类品的表征建模更加准确,避免了C品低估问题,也确保了售出及下架的优质C品的表征能够持续更新,对推荐系统形成持续的正向反馈。
从更本质的角度看,C2C平台的浅库存商品预估不准,就是由其交互数据少导致的Embedding表征学习不充分造成的。一种直观的解法就是对商品“打包”,即针对一系列相似属性的商品构造相同的聚类ID,同一聚类ID下的商品共同积累用户对这个聚类ID下的交互数据——通过这种方式,可以让交互稀疏的C类品享受到其相似B类品丰富交互信息的福利,或者让多个相似的C品共享用户的交互数据,加速C品Embedding的学习和收敛,提升对C品的预估能力。
综上,孤品建模的关键问题有两个:
1)如何构造聚类ID,或者换句话说,如何在不依赖用户交互数据的前提下,衡量两个商品是否相似,相似程度多高;
2)假设我们已经构造出了商品聚类ID,如何应用到排序模型当中,在保证B类品效果的同时,进一步提升C品的预估准度。
近邻分析
一个商品包含静态属性和动态属性,其中动态属性即用户的交互数据,而静态数据由文本信息和图片信息构成。孤品的动态数据不足,因此我们期望从文本和图片两个维度,构建商品的相似信息。从文本角度来说,我们通过商品的叶子类目、品牌、文字描述实体的叉乘,构建商品的Spu_id。从图片角度来说,此外还有商品的图片聚类ID。
基于近邻扩展的孤品建模方案
如何将这种相似近邻信息融入排序模型?
历史实验表明,直接将候选商品所属的图搜聚类(ImgID)和文本聚类(SpuID)作为简单特征引入模型(和其余所有特征Concat在一起之后作为DNN层的输入)无法给模型带来正向的收益,几个可能原因:1)基线模型水位较高,输入特征超过200个,总维度超过2000维,单纯引入两个新特征的信息难以被模型捕捉;2)这两个新特征的hashBktSize达到亿的量级,直接作为DNN特征引入模型从零开始训练,新增后续DNN的节点权重小,根据链式法则分配到的梯度小更新慢,导致Embedding难以收敛。
针对上述直接引入特征的失效问题,解决思路有两步:1)为模型设计专门的结构,更好地捕获新特征的信息,防止信息淹没;2)尽可能让新特征在模型的更多结构中出现,这样一轮“前向+后向”传播过程可以对新特征进行多次梯度更新,加速学习和收敛。